I have recently decided to take a quick look back to a problem I haven’t spent much time to solve, namely my results on the Reuters dataset. One of my problems was due to inconsistent results between my experiments and the published results by Ranzato and Szummer.
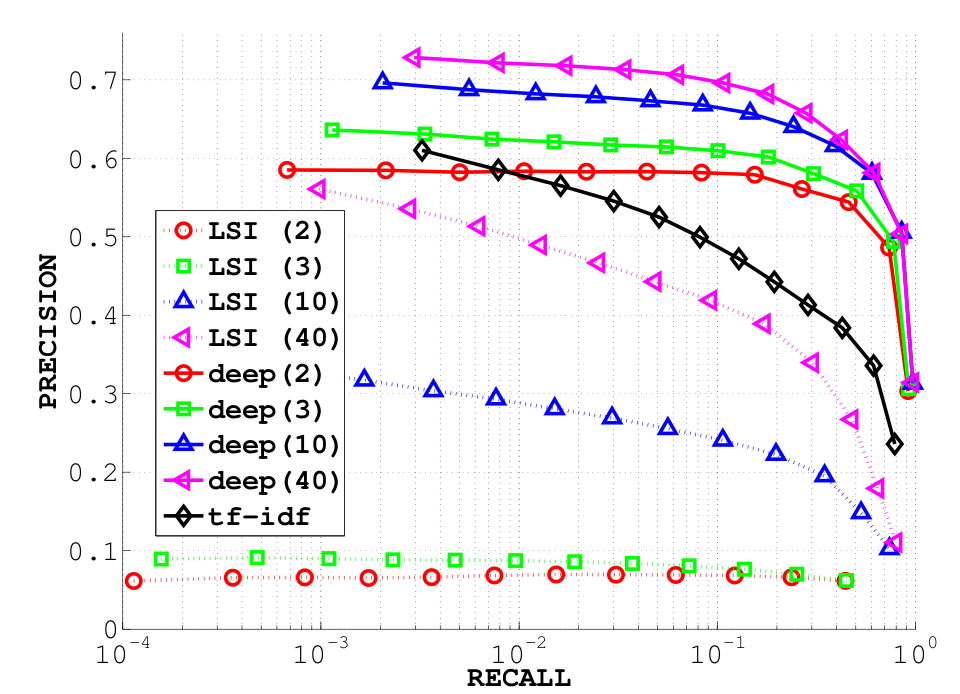
I have already talked about their paper in previous posts, and NC-ISC outperforms their method on the 20 newsgroups dataset (they haven’t published any precision/recall curve on Ohsumed). On the small Reuters dataset, though, they have very good results, and they also publish some material that I have a hard time reproducing. The figure 4 of their paper « Semi-supervised learning of compact document representations with deep networks », especially, compares results from LSI and from their method. The problem is that my own experiments show much better results for LSI.
Their results :
And my results (just LSI) :

To sum up : my results for LSI-2 starts with a precision of 0.35 while theirs starts with a precision of 0.06, LSI-10 respectively starts at 0.57 versus 0.35, and LSI-40 at 0.68 versus 0.56.
What is really surprising (even though, technically, not completely impossible) is that their results for LSI-2 and LSI-3 are below the baseline one could obtain by randomly choosing documents. My TF-IDF curve is relatively close to theirs (even though not exactly the same).
Since they have taken the data from the same source I have, I really don’t understand how we can have such different results.
Another puzzling fact is that, on the Reuters dataset, TF-IDF actually performs worse than cosine distance on the raw counts (at least for a recall below 1%). This is, I think, the only dataset with such a behaviour.