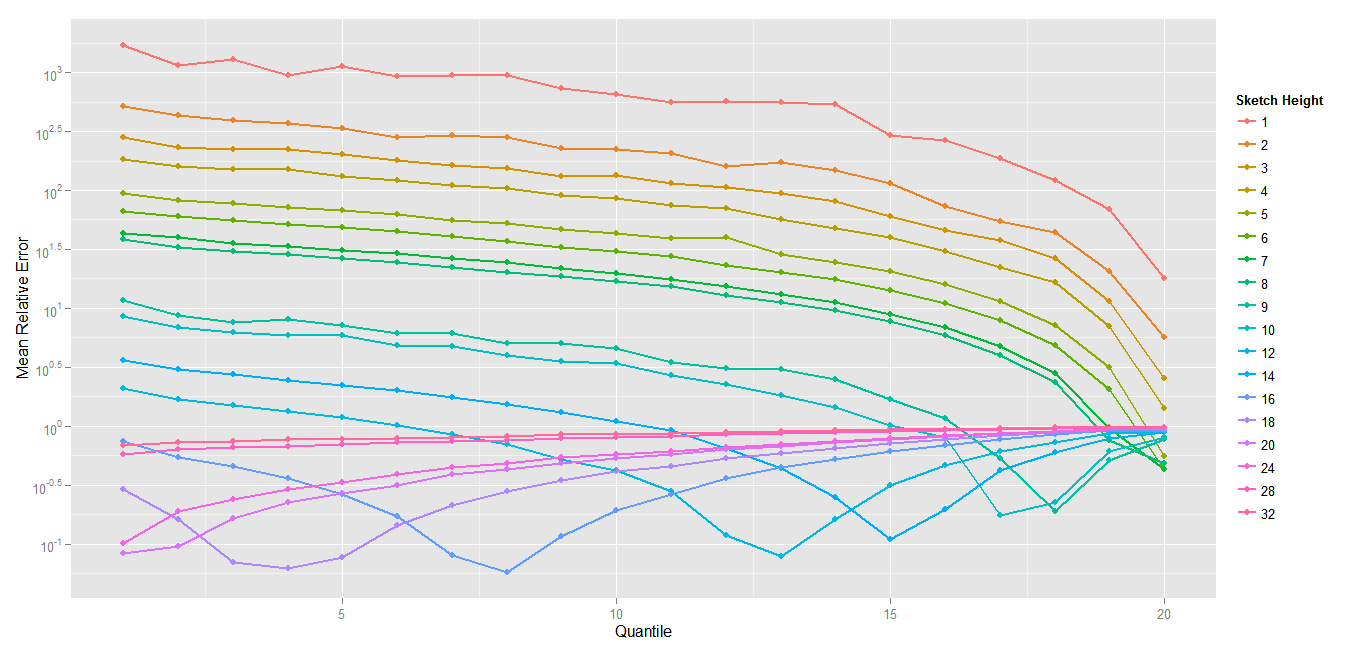
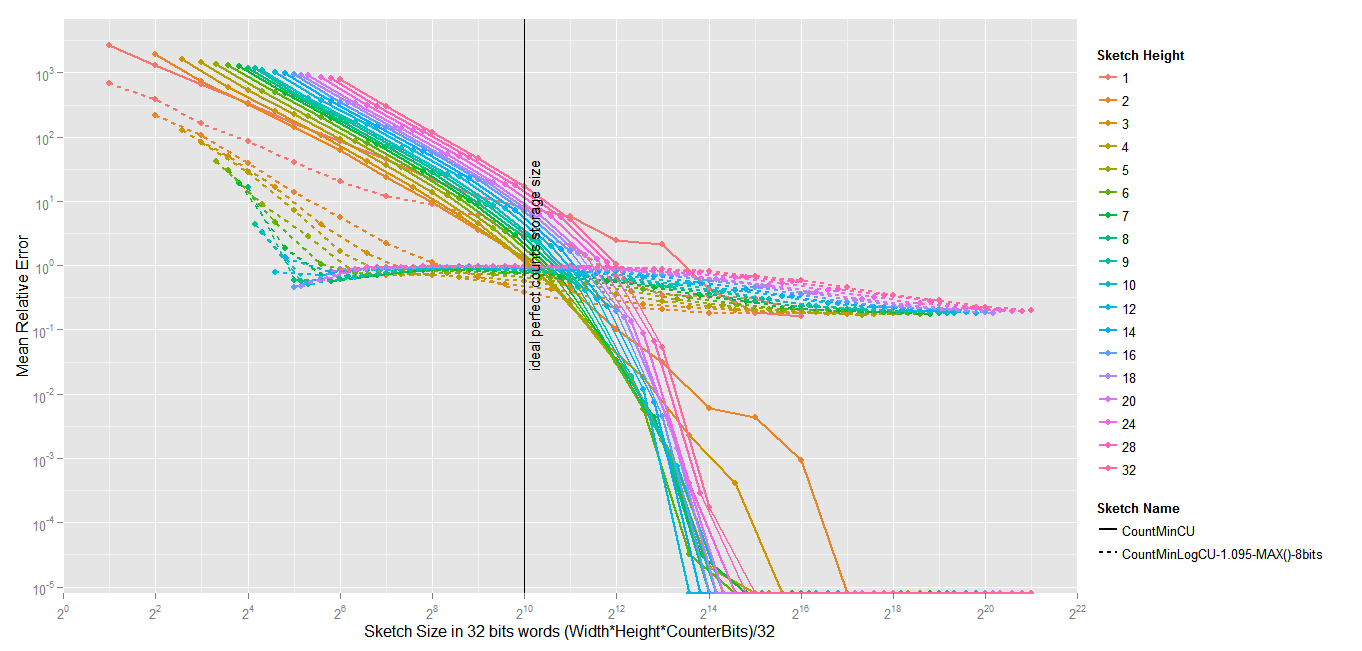
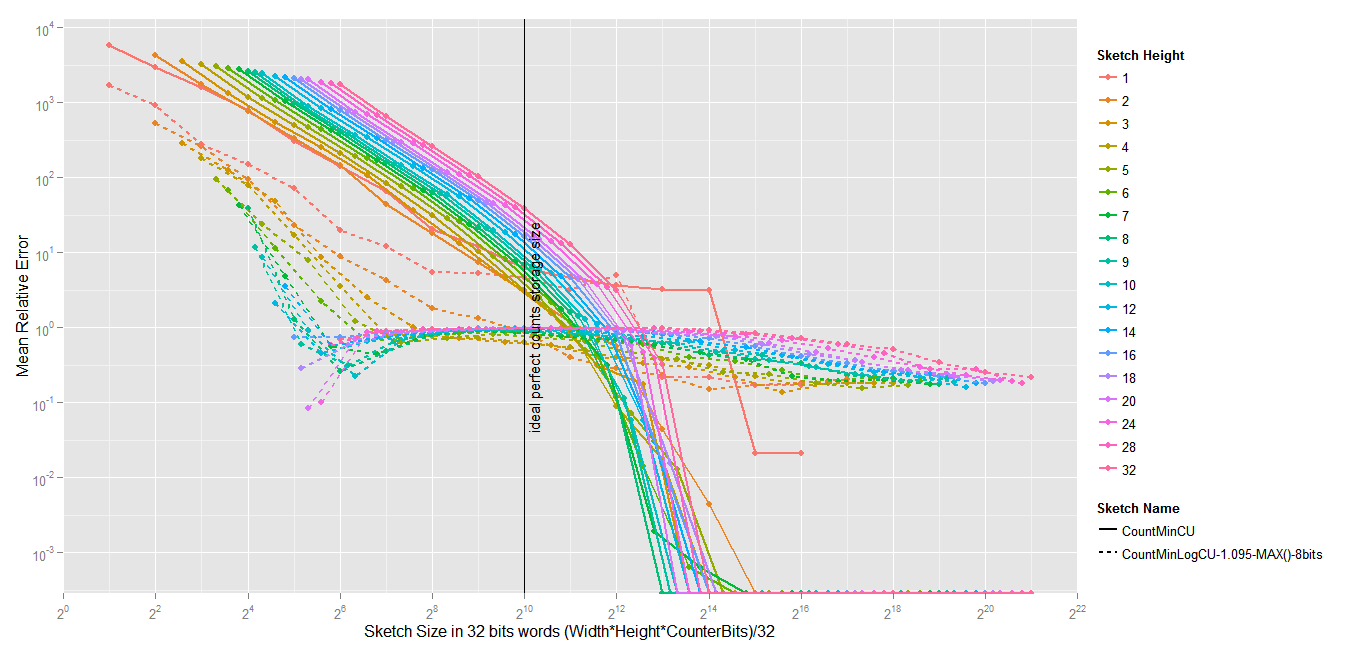
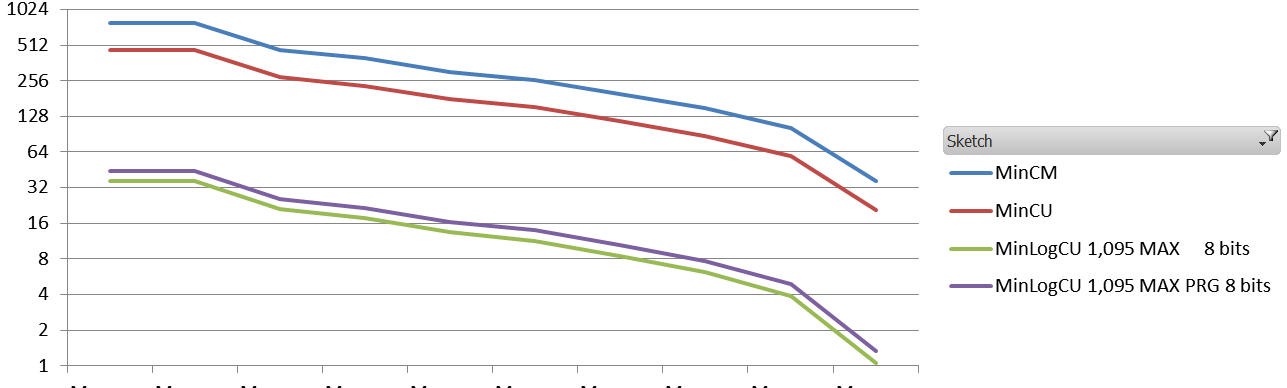
Does SGNS (Word2Vec) encodes word frequency ?
I’ve been wondering for a while about the behaviour of SGNS vs SVD/PMI with regards to the difference of performance on analogy questions. (Have a look at Omer Levy’s TACL article for a deep comparison of different methods).
One of my hypothesis is that, somehow, SGNS encodes the frequency of the words in its embedding. I think (haven’t tested it yet) that using frequency could help for many analogy questions, since one would expect, on average, that the frequency ratio between A and B is the same than between C and D.
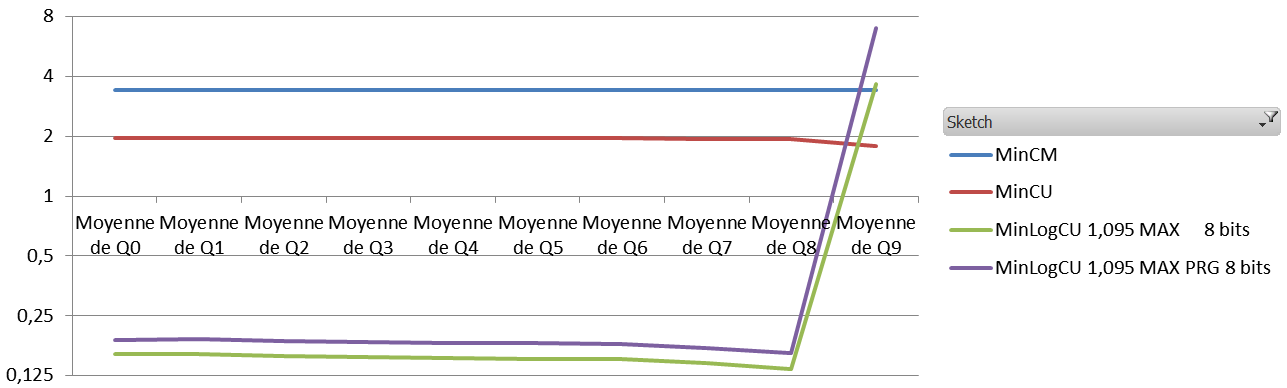
One of the thing that made me think that SGNS could encode frequency is when I look at the neighbours of rare words :
With SVD (in parenthesis, the count from context with window size = 2):
| 1.0 | iffy | (279) |
| 0.809346555885 | nitpicky | (125) |
| 0.807352614797 | miffed | (69) |
| 0.804748781838 | shaky | (934) |
| 0.804201693021 | sketchy | (527) |
| 0.797617651846 | clunky | (372) |
| 0.794685053096 | dodgy | (797) |
| 0.792423714522 | fishy | (494) |
| 0.7876010544 | listy | (211) |
| 0.786528559774 | picky | (397) |
| 0.78497044497 | underexposed | (73) |
| 0.784392371301 | unsharp | (130) |
| 0.77507297907 | choppy | (691) |
| 0.770029271436 | nit-picky | (90) |
| 0.763106516724 | fiddly | (43) |
| 0.762200309444 | muddled | (369) |
| 0.761961572477 | wonky | (196) |
| 0.761783868043 | disconcerting | (226) |
| 0.760421351856 | neater | (121) |
| 0.759557240261 | dissapointed | (32) |
Variation : 0.1 – 3 x the query count
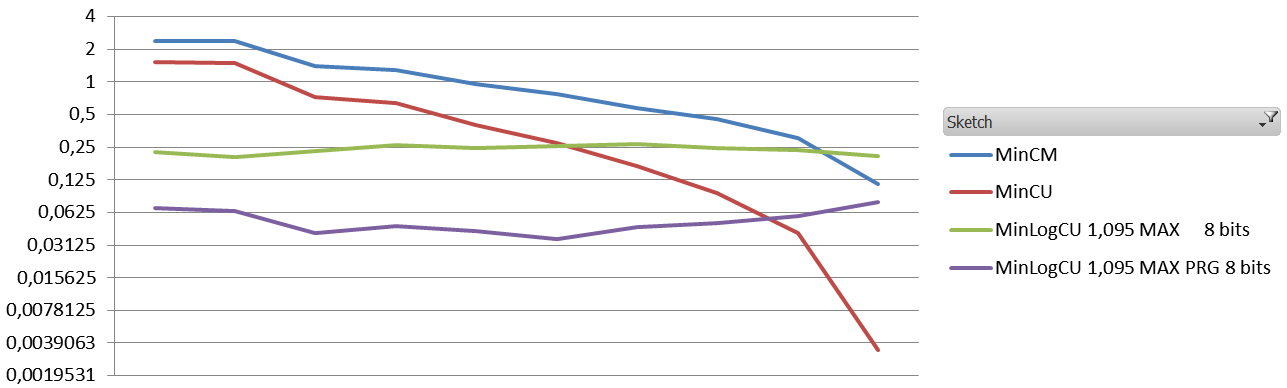
With SGNS :
| 1.0 | iffy | (279) |
| 0.970626 | nitpicky | (125) |
| 0.968823 | bitey | (265) |
| 0.968336 | rediculous | (104) |
| 0.967125 | far-fetched | (262) |
| 0.964707 | counter-intuitive | (185) |
| 0.964179 | presumptuous | (126) |
| 0.963679 | disputable | (179) |
| 0.963537 | usefull | (183) |
| 0.96175 | clunky | (372) |
| 0.96166 | counterintuitive | (203) |
| 0.961654 | un-encyclopedic | (101) |
| 0.961331 | worrisome | (213) |
| 0.960878 | self-explanatory | (156) |
| 0.960516 | unecessary | (143) |
| 0.960142 | nit-picky | (80) |
| 0.959044 | wordy | (413) |
| 0.958482 | disconcerting | (226) |
| 0.958218 | disingenuous | (534) |
| 0.958188 | off-putting | (104) |
Variation : 0.3 – 2 x the query count
That could actually be quite understandable. Since the update procedure of SGNS is online, the time of the update does have an importance (vectors at time t in the learning are not the same than at time t+s). So two rarely occuring words, if they occur roughly at the same time in the corpus, will tend to be updated by a few similar vectors (positively and negatively, by the way), and thus be highly influenced by the same direction of the data.
In other words, the rarer the word, the more its direction “lags behind” the rest of the embeddings, and in some way, the embedding slightly encodes the “age” of the words, and thus their frequency.
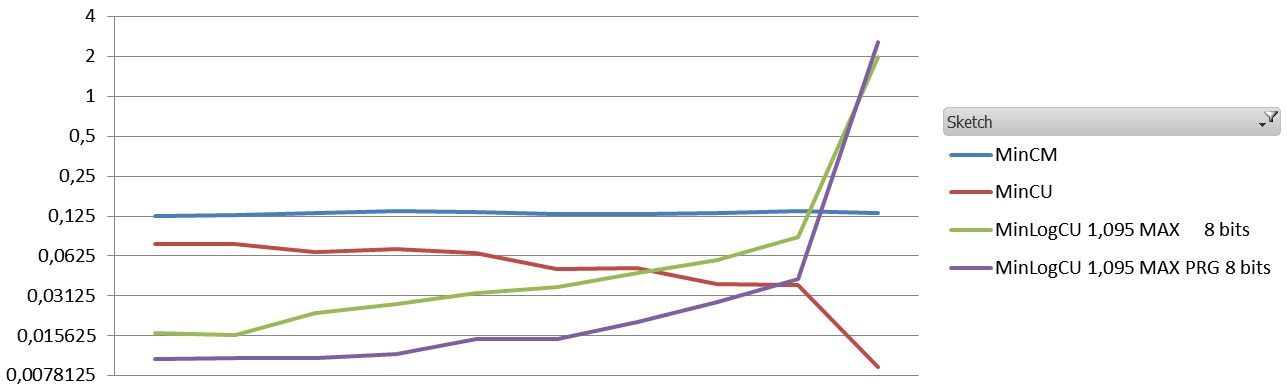
Here are its results on the same query with NCISC, with even more variation than SVD, with some apparently good high frequency candidates (debatable, unclear, unsatisfactory, questionable, and maybe wrong) :
| 1.0 | iffy | (279) |
| 0.840267098681 | debatable | (711) |
| 0.835281154019 | keepable | (67) |
| 0.83013430458 | disputable | (179) |
| 0.821933628995 | sketchy | (527) |
| 0.813930181981 | unsatisfactory | (1176) |
| 0.812291787551 | unclear | (4445) |
| 0.804978094441 | nitpicky | (125) |
| 0.804038235737 | us-centric | (170) |
| 0.802013089227 | dodgy | (797) |
| 0.798211347285 | salvagable | (118) |
| 0.797837578971 | shaky | (934) |
| 0.797040400162 | counter-intuitive | (185) |
| 0.79600914212 | ambigious | (41) |
| 0.791063976199 | offputting | (33) |
| 0.789877149245 | questionable | (6541) |
| 0.789543971526 | notible | (78) |
| 0.786470266284 | unconvincing | (567) |
| 0.781320751203 | wrong | (12041) |
| 0.779762440213 | clunky | (372) |
Variation : 0.1 – 43 x query count