I’ve made a few experiments to have a look at the behaviour of the Count-Min-Log Sketch with Max sampling. Here are some interesting comparisons between classical Count-Min (the graphs show both the usual CM algorithm and the Conservative Update version), and Count-Min-Log.
For the sake of simplicity, I’ve chosen to limit to one setting in terms of memory use : in every sketch we use the same number of bits (here, 4 vectors of 4000*32 bits). I have also just shown the result of 8 bits Count-Min-Log (i.e. with base 1.095) with or without the progressive base (PRG).
Let’s start by the results under heavy pressure. Here we have 8 millions events in an initial vocabulary of 640,000 elements. The values are plotted for each decile of the vocabulary (i.e. on the left is the first 10th of the vocabulary with the lowest number of occurrences).
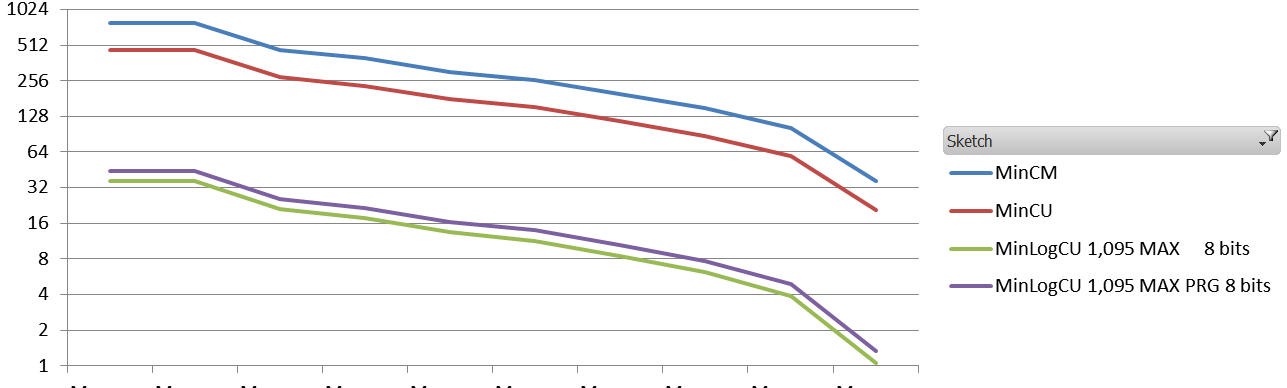
Average Relative Error per decile for high pressure setting.
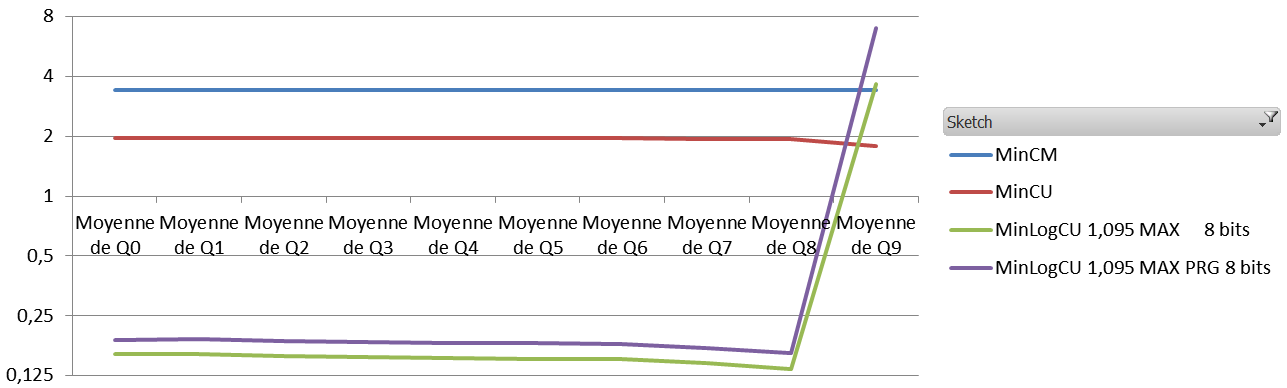
Root mean square error per decile for high pressure setting.
Now for the low pressure setting, still with 4 vectors of 4000*32bits for everyone, but this time the initial vocabulary is only 10000 and the number of events is about 100k.
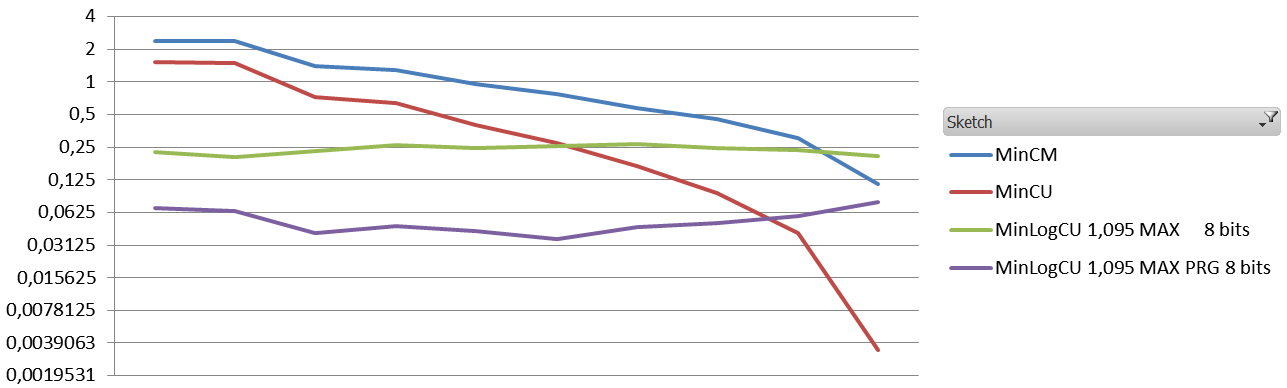
Average Relative Error per decile for low pressure setting.
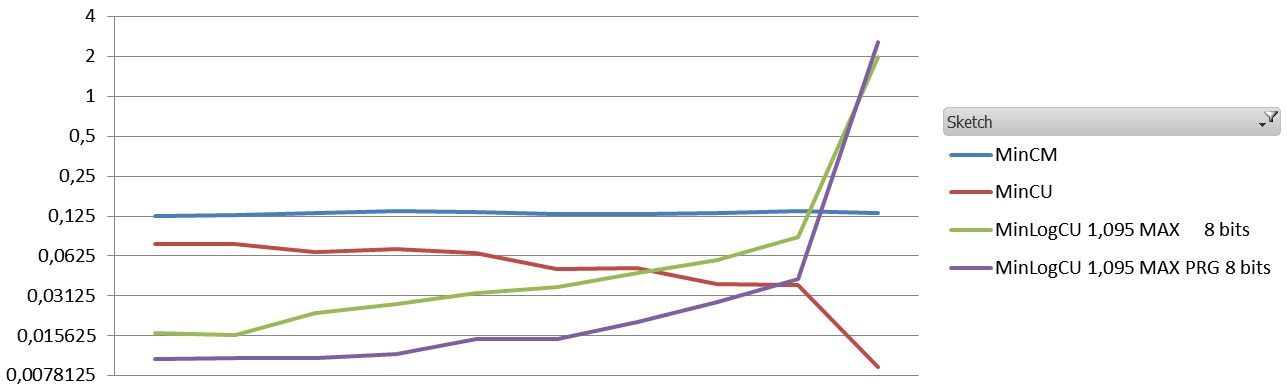
Root mean square error per decile for low pressure setting.
Conclusion, for equal memory footprint, Count-Min-Log seems to clearly outperform classical Count-Min for high pressure settings, both for RMSE and ARE, with the exception of the RMSE for the top 10% highest frequency events. Under low pressure, it is clear that top 20-30% highest frequency items counts are significantly degraded.
I think that for any NLP-related task, Count-Min-Log is always a clear winner. For other applications, where the highest frequency are the most interesting, the gain may be negative, given the results on the high pressure setting. It will depend whether you care about ARE or RMSE.
Comments are closed, but trackbacks and pingbacks are open.