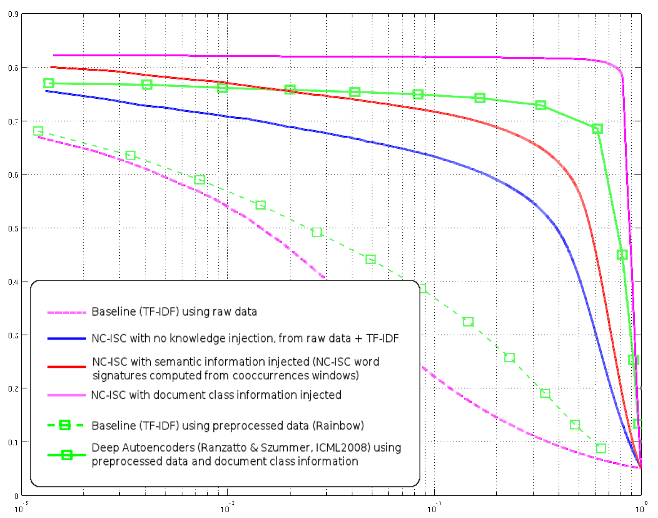
I made a big mistake in my last post about our results improvements, the precision/recall curves of our experiments were in « gain » mode, that is, the curve tend toward zero as it approach the precision of a random selection. As a result, instead of finishing at about 5% precision (for a 20 classes problem with balanced classes, that’s what one should obtain). So our actual result are even slightly better than what you saw in my previous post.
More importantly, I’ve included here another variant of semantic knowledge injection, this time using bi and trigrams in addition to normal words (for instance, « mother board » is now considered as a unique vocabulary item) – the bi and trigrams are automatically selected.
The vocabulary size climbs from about 60K to 95K, with many grammatical constructs (« but if » and such), and the results are quite amazing : an improvement of precision of 4-5% on the left, and about +10% precision toward the 0.1 recall mark.
This is probably a more important result than what we’ve achieved with class knowledge injection, since class knowledge is rarely available in real world problems (in the case of product recommendation, you don’t know the class of your users, for instance).
The fact that our method, using only inner knowledge, can outperform, up to the 2% recall mark, the Deep Autoencoders using class knowledge, is probably more important than any result I could have only using class information.
 )
)