Despite the already good results of our method, we have further improved it. The most notable improvement is due to a better handling of the numeric compatibility between the two final embeddings (for instance words and documents embedding).
Here are the results on 20newsgroups-bydate (60% training, 40% testing, test data correspond to the latest documents in time).
This was also the occasion for us to show how simply injecting »a priori » knowledge about word semantics can significantly improve the results (this »a priori » knowledge is computed using NC-ISC on a cooccurrence matrix, using a 20 words window on a mix of 20newsgroups and reuters RCV1 corpus).
The curves are classical precision/recall results. For comparison, I have included what I think are the best results in the state of the art (I have missed more recent results, please tell me) from Ranzatto & Szummer (ICML 2008) from their figure showing their best results of the shallow method (I have no clue as to whether their deep method can do any better, but I doubt it since they mainly argue that deep methods can perform as well as shallow method but with less features).
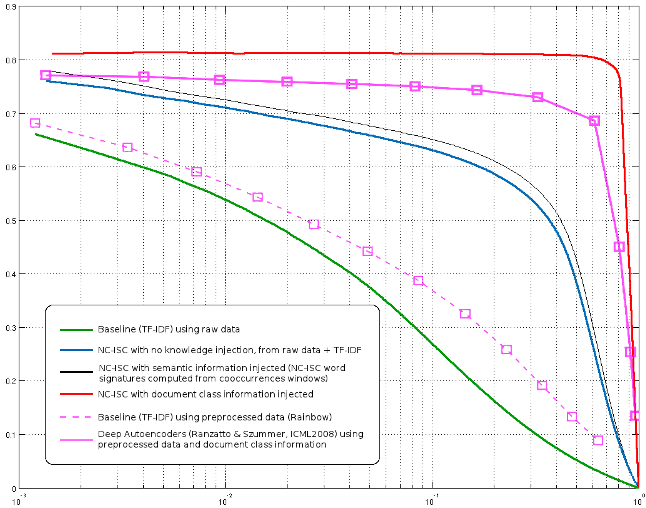
One interesting thing is that Ranzatto and Szummer use a preprocessed 20 newsgroups corpus that reduce their vocabulary to 10000 (using Rainbow), while we use pure raw words (including uppercase and lowercase variants). It would be interesting to see wether their method could perform better if they were to use the whole unprocessed vocabulary. Also, our first experiments using frequent pairs and triplets of words as new vocabulary items has shown an unexpected global performance decrease (this concern raw TF-IDF as well as all NC-ISC variants). Comments on this are warmly welcome.