As a followup to my researches on documents and / or vocabulary characterizing, we are preparing (some friends and myself) to launch a new recommendation service. Our first targets are eCommerce sites that can greatly benefit some improvement over the products they show to the users (whether it’s in the recommended items list or in the display order of a search query). Amazon reportedly has a 30% share on its sales that directly comes from recommended items (and their recommendations are not unanimously acclaimed). Now the question will be : why will my algorithm be better than the others ? and why should you use it.
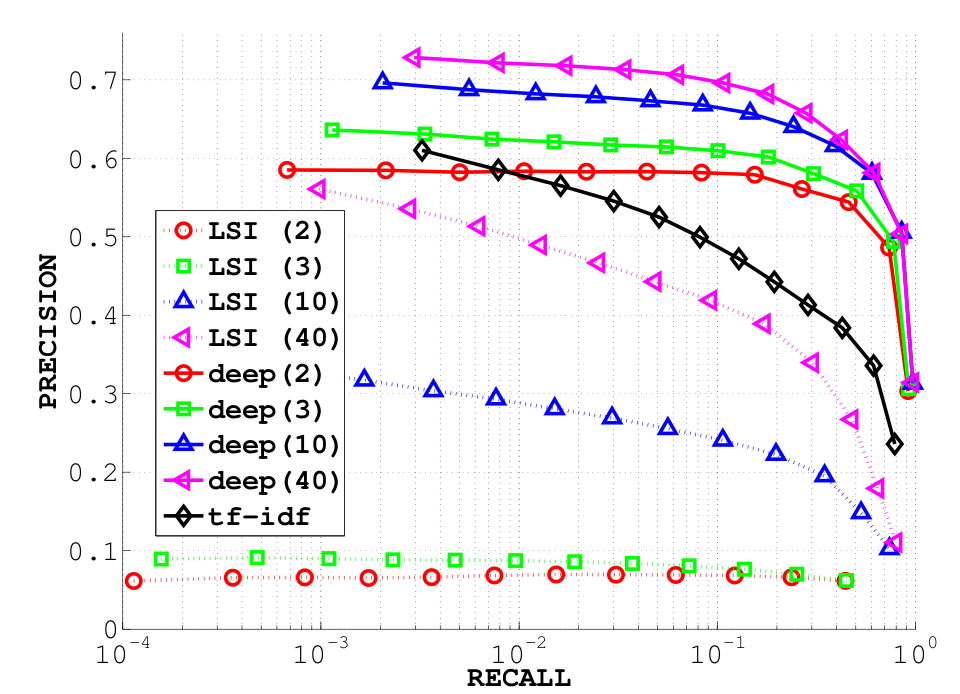
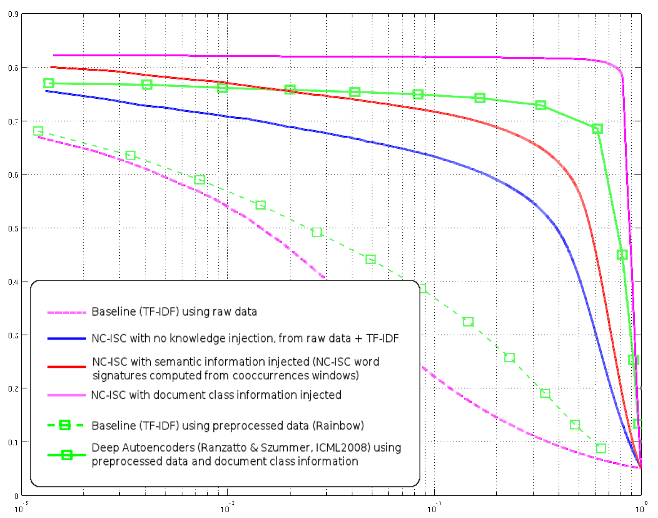
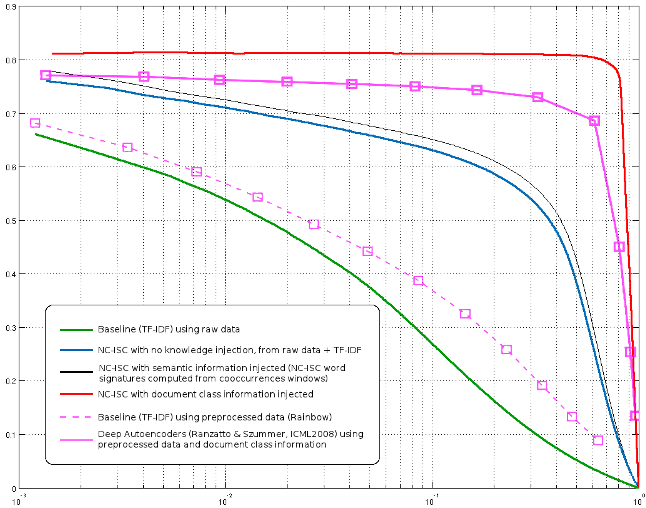
As stated in this article, the data you collect is more important than the algorithm you use. That will always be true : with no data at all, the best algorithm will always perform worse than a clumpsy algorithm working on tons of excellent and clean data. That’s almost tautological, but sadly true, no miracle can come only from the algorithm. Now, if you do your best at collecting data, then the algorithm can make a real difference (take for example my article about the 20 newsgroups experiments : while most high performance existing algorithms can only take into account a few words, mine does much better because it can seemlessly handles all available data. Also, in my previous note about Ohsumed, I show that with exactly the same data, my algorithm NC-ISC can largely outperform other state-of-the art methods.
Now that you’re persuaded that my algorithm works for document retrieval, I must convince you that it will also work on other topics : recommendation / collaborative filtering is a quite standard task in machine learning community, and it has already gathered a lot from computational linguistics methods (see RSVD for instance). The idea is this : in both cases (information retrieval and recommendation systems) we have a few relational information between type A objects and type B objects.
In IR, type A are words, type B are documents, the relation being the fact that a word appears in a document. In recommendation systems, we have users as type A objects and products as type B. The relations can be “view”,”buy”,”put in basket”, etc.
In both case, the idea is to fill the blanks in the matrix, or, to guess the strength of the relation between any A object and any B object, wether they have been observed before or not.